
취미와 밥줄사이
[MachineLearning] - KNN 본문
KNN (K-Nearest 0Neighbors)

- 새로운 데이터 생겼을 때, 이를 어디로 분류해야 할까요?

- 왜 빨간색으로 분류를 했을까요?
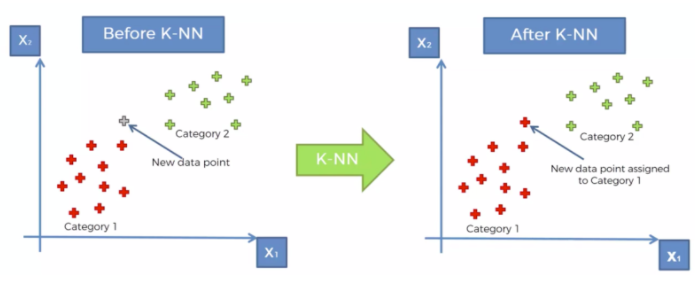
KNN 알고리즘
** - 내 주위에 몇 개의 이웃을 확인해 볼 것인가를 결정한다. == > K**

- 새로운 데이터 발생 시, Euclidean distance에 의해서, 가장 가까운 k개의 이웃을 택한다.

- K개의 이웃의 카테고리를 확인한다.

- 카테고리의 숫자가 많은 쪽으로, 새로운 데이터의 카테고리를 정해버린다.
